Building a Password Recovery Queue
March 1st, 2023 by Oleg AfoninCategory: «General»
In the previous article we discussed the different methods available for gaining access to encrypted information, placing password recovery attacks at the bottom of the list. Password recovery attacks are one of the methods used to gain access to encrypted information. In this article we’ll discuss the process of building a password recovery queue. Learn how to choose the appropriate workflow for the attack, the first prioritizing files with weaker protection, the second prioritizing faster and shorter attacks, and the third being a combination of the two. For your reference, we built a table to compare the relative strength of different file formats and encryption methods, helping users prioritize their attack queues.
Building the password recovery queue
The password recovery workflow consists of an ordered queue of individual jobs. Each job specifies a single attack on a single file. You may set up a queue consisting of multiple attacks on a single file, or attack multiple files. For example, your queue may look like this:
Workflow 1: File #1 ------ Attack #1 ------ Attack #2 ------ Attack #3 File #2 ------ Attack #1 ------ Attack #2 ------ Attack #3 File #3 ------ Attack #1 ------ Attack #2 ------ Attack #3
When you opt for the first workflow, files with the weakest protection should be on the top of the queue, while formats with the slowest attacks should be placed at the bottom. This workflow prioritizes files with weaker protection over faster and shorter attacks. However, you can also set up the queue like this:
Workflow 2: File #1 ------ Attack #1 File #2 ------ Attack #1 File #3 ------ Attack #1 File #1 ------ Attack #2 File #2 ------ Attack #2 File #3 ------ Attack #2 File #1 ------ Attack #3 File #2 ------ Attack #3 File #3 ------ Attack #3
If you opt for the second workflow, the queue will be ordered with the shortest attacks first, while longer and time-consuming attacks take the bottom of the list. This workflow prioritizes faster and shorter attacks over weaker protection.
Of course, nothing should stop you from combining the two approaches. For example, a classic example of Workflow 1 may look like this:
Newdocument.docx ------ Dictionary attack top-10000 ------ Digit only passwords (1-6 digits) ------ Dictionary attack with mutations English.udic ------ Dictionary attack with mutations Spanish.udic ------ Brute force attack (1-8 characters) Expenses.xlsx ------ Dictionary attack top-10000 ------ Digit only passwords (1-6 digits) ------ Dictionary attack with mutations English.udic ------ Dictionary attack with mutations Spanish.udic ------ Brute force attack (1-8 characters)
However, the brute force attack on the first file may take forever, while a dictionary attack may end in reasonable time. You may want to modify your attack with an element of the second workflow, in which case your password recovery queue may look like this:
Newdocument.docx ------ Dictionary attack top-10000 ------ Digit only passwords (1-6 digits) ------ Dictionary attack with mutations English.udic ------ Dictionary attack with mutations Spanish.udic Expenses.xlsx ------ Dictionary attack top-10000 ------ Digit only passwords (1-6 digits) ------ Dictionary attack with mutations English.udic ------ Dictionary attack with mutations Spanish.udic Newdocument.docx ------ Brute force attack (1-8 characters) Expenses.xlsx ------ Brute force attack (1-8 characters)
Notice that in the second example we moved the most time-consuming attack (the brute-force) to the bottom of the queue for both files. This makes sense if the files in the queue have similar encryption strength. However, if there is a big difference in attack speeds between the files, you may have a better chance of success with the first type of workflow, placing the weakest protected files on top of the queue.
Choosing the right workflow
Which of the two workflows should you choose when attacking a password? We have already discussed the “low hanging fruit” strategy (e.g. May the [Brute] Force Be with You!) where you would generally target data formats protected with weakest encryption. There is another side to “low hanging fruit”: attempting short, limited-time attacks on other formats before launching a longer attack on the weaker formats. Generally, you would place the fastest and shortest attacks on the top of the queue, with longer, time-consuming attacks taking the bottom of the list. The “Top-10000 passwords” attack will be fast on nearly every format. A dictionary attack with mild mutations may be already too slow on some formats but still meaningful on the others. To help you prioritize your password recovery queue we built a table comparing the relative strength of the different formats. WinZIP AES-256 will be the point of reference with the value of “1”. Attacks on NTLM passwords are nearly 45,000 times faster on the same hardware, while attacks on RAR5 archives are almost 10 times slower.
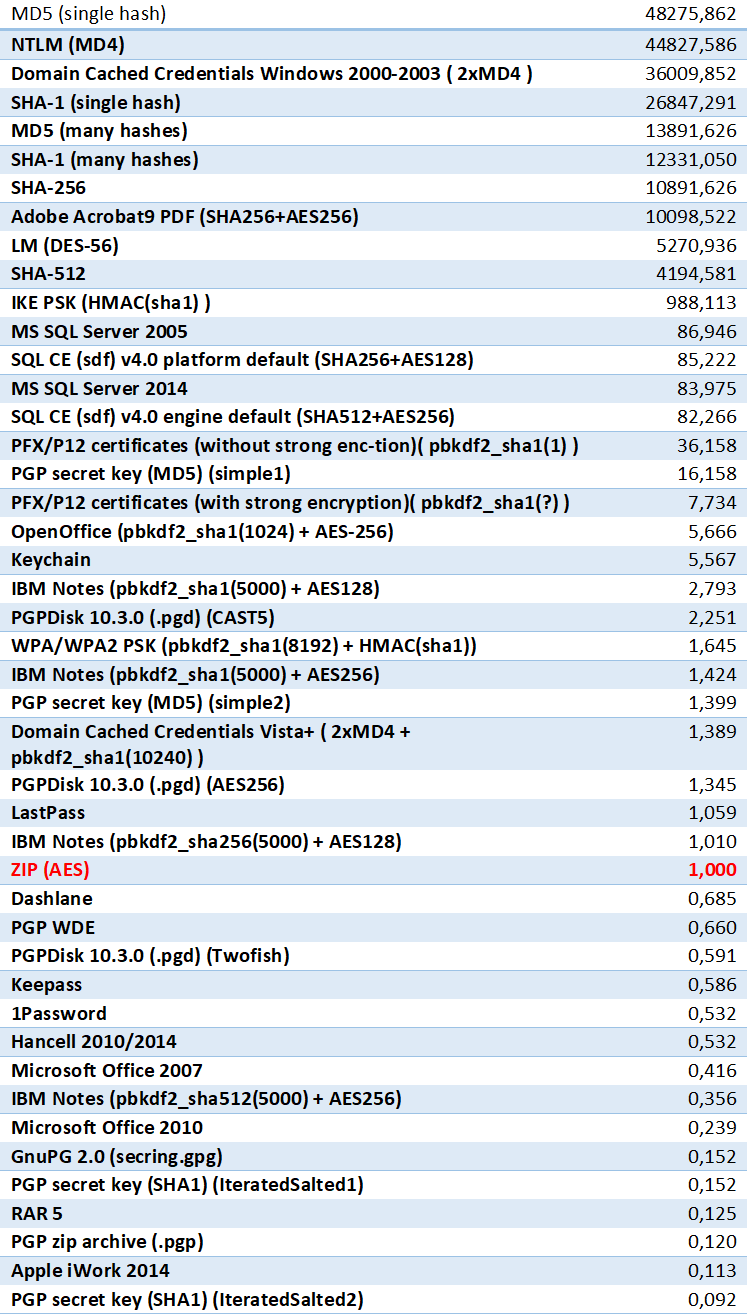
This table demonstrates that if you have a mix of files and hashes to break, it might be beneficial to attack NTLM passwords and individual hashes first if they are parts of the queue, making it a Workflow 1. If, however, you have a bunch of ZIP and RAR archives as well as a number of Microsoft Office documents, their relative protection strength is so close that you may ignore this factor and set up the attack as demonstrated in the Workflow 2.
The practical steps
Considering the above, we recommend setting up the following attack pipeline in Elcomsoft Distributed Password Recovery.
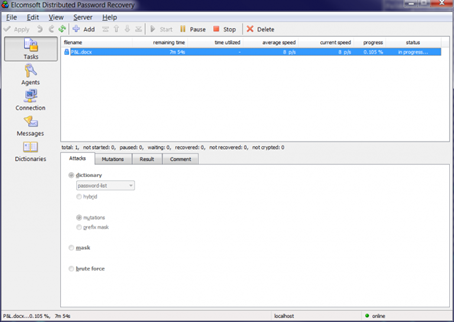
- Use Top 10,000 password list and set up a straight dictionary attack as shown here:
- Add a digit-only attack. Limit the length of the passwords to 8 digits (for formats with stronger protection limit to 6 digits).
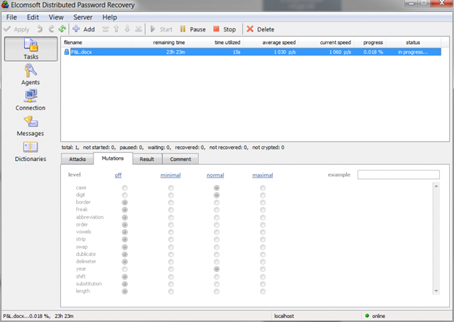
- Make use of the dictionary of English language followed with an attack based on the dictionary of your local language. Configure the attack using medium mutations as shown below:
- If none of that worked, estimate your chances with a brute-force attack. You may still use masks and rules to throw out some very random passwords.
Conclusion
The password recovery process involves a queue of sequential jobs, each job representing a single attack on a single file. The queue can be set up in many different ways. We recommend one of the two setups: you can place the multiple attacks on a single file first, or attack multiple files with multiple attacks, placing the fastest and shortest attacks at the front of the queue.
The choice of workflow depends on the relative protection strength of files and hashes to be broken. A table comparing the relative strength of different formats will help prioritize the password recovery queue. In the first workflow, files with the weakest protection are placed on the top of the queue. Then, for each file, the fastest and shortest attacks are placed at the top, while longer and time-consuming attacks take the bottom of the list. In the second workflow, the most time-consuming attacks are moved to the bottom of the queue for all files. Ultimately, the choice of workflow will depend on the specific mix of files and hashes to be broken and their relative protection strength.

- iOS Forensic Toolkit 9.0: full unlocking and perfect acquisition support for iPhone 6/6 Plus and other Apple A8/A8X devices11 February, 2026
- Elcomsoft Quick Triage30 December, 2025
- Introducing free forensic tools12 December, 2025
- Elcomsoft System Recovery 8.36 adds Windows Server 2025 support, BitLocker key exporting, and enhanced SRUM analysis14 November, 2025
- iOS Forensic Toolkit 8.81 adds iOS 17 and 18 support for checkm8 extractions 6 November, 2025