Leveraging User Profiles for Smarter Password Attacks
November 24th, 2025 by Oleg AfoninCategory: «General»
Most real-world passwords aren’t random – they follow the owner’s habits, preferences, and personal history. Names, birthdays, pets, team loyalties, and even old usernames affect how people build their “secret” strings. By turning this everyday information into structured, prioritized password candidates, analysts can reach higher success rates than with generic dictionaries or blind brute force. This article explains how to transform user data into a focused attack strategy.
We’ll walk through the entire workflow: extracting meaningful tokens from a user profile, converting them into templates, applying masks and rule-based mutations, and producing a compact, efficient dictionary tailored to a specific person. The goal is not to generate huge wordlists, but to generate the right ones – candidates that reflect the user’s real behavior. With practical examples and EDPR-compatible syntax, we’ll provide a reproducible method for building smarter, more effective password attacks from user-centric data.
The Problem
In a typical investigation, a forensic specialist may receive an encrypted disk, a locked container, or a bunch of encrypted files belonging to a suspect. The task is clear: gain access to the data, which means recovering the password. In many cases, a pre-configured “cold” attack is launched using generic dictionaries, mutations or masks. However, investigators often know things about the suspect: their name, nicknames, family members, maybe pets, dates of birth, anniversaries, and perhaps other things. This information is obviously relevant: almost every password-creation study shows that personal details frequently end up inside passwords. Yet the common advice investigators get, in articles and even in some training materials, is frustratingly vague: “Use personal data to build targeted attacks.” How exactly? What should you actually do with the collected information? These critical, practical steps are almost never explained outside of specialized training sessions.
Where User Data Comes From
The personal information used for targeted attacks usually arrives through two channels. First, the investigator or case officer gathers it – interview notes, social media traces, subscriptions, contacts, and anything else that describes the suspect’s environment. Second, the forensic specialist may receive a compiled profile summarizing the suspect: name variations, known usernames, important dates, pets, places, and cultural preferences. In addition, some information may also come from seized devices (metadata, chats, browser profiles etc.) The challenge is that this profile is written for humans, not for password-cracking software. It contains raw facts, but none of it can be fed directly into a dictionary or mask. Before it becomes useful, the data must be reshaped into something predictable, consistent, and machine-friendly.
The Tokens
People rarely use the data verbatim, but it often forms the base they modify using predictable patterns. To make the suspect’s personal data usable in password attacks, the first step is to break it down into tokens. A token is a small, clean unit of information that can serve as a building block for password candidates. In practice, tokens are standardized pieces of text: lowercased names (“michael”), short forms and nicknames (“mike”, “micha”), family names (“garcia”), numbers extracted from dates (“1991”, “0317”), and meaningful keywords (“milo”, “celtics”, “batman”), perhaps extracted from the user’s existing passwords. These tokens should be regularized – lowercase, stripped of punctuation, consistently formatted, so that templates, masks, and mutation rules can operate on them without ambiguity. Once the entire user profile is converted into tokens, they can be combined, expanded, and mutated in systematic ways to form a focused dictionary that reflects how the suspect is likely to build passwords.
Here is a practical example. Let us say we have a profile filled with some useful data, such as: first and last names, nicknames, names of relatives, pet names, birthdays, anniversaries, sports teams, favorite movies or characters, and known online usernames.
To keep this manageable, everything should be normalized first. That means:
- Lowercase the text: “Michael” – “michael”
- Create additional, separate entries for tokens with accents or special characters (keep the original, too): “josé” – “jose”
- Remove spaces and punctuation
- Extract different date versions: 1984-07-12 – 1984, 07, 12, 19840712, 12071984, etc.
After normalization, create a seed list of tokens such as:
- Names: michael, mike, micha, m, garcia, g (this allows generating concatenations such as “mgarcia”, “m.garcia” or “mikeg”)
- Pets: fluffy, luna
- Dates *: 1984, 840712, 120784
- Teams: lakers, barcelona
* While these bits of data can be replaced with a “date” mutation when you actually run the attack, they still remain valuable and worth having on separate lines. Note that date representations can be affected by regional formatting.
These tokens will later be combined into templates and expanded into real password candidates. With a normalized token set, you now have the raw material needed for templates and masks
Token priorities
Not all tokens are equally important. You need a simple way to rank them so the system tries the most likely combinations first. Two things determine priority: how common something is in passwords in general, and how relevant/important something is for a given person (this, for example, can be deducted from their social networks or by analyzing the list of their existing passwords, if available). The latter is more important (has a greater weight) than the former.
This is how it works in practice. First names show up a lot in leaked password sets. Some words like love, sunshine, dragon, or sequences like 123 appear extremely often. If something is common globally, give it a small bonus. Which words in particular? Only practical experience can tell which words, names, or languages are more common in your area; generalizing on the “ten million passwords” leak is not the best idea.
Example:
- “john” is a common name but not the name of the suspect or their circle, so medium priority
- “love” – very common; lower priority on its own, higher when combined with personal tokens
- “fluffy” – rare globally, but high priority if known to be the user’s pet
- “12345” – common but not personal – low priority
Personal relevance usually outweighs global frequency.
Example:
- Pet name “fluffy” (from a social media post) – high priority
- First name “michael” (suspect’s name) – high priority
- Team “barcelona” (from profile picture) – medium priority
- “071284” – personal date – high priority
Final score will be a rough combination of “how common” and “how personal” the token is. This does not need to be precise math. The goal is to sort tokens from “very likely” to “unlikely but possible” and decide which words make it into the case-specific dictionary, and which don’t.
Templates
After you build your targeted dictionary, the next step is making password patterns from the tokens. Templates are simple patterns that describe how users (or the given person) build their passwords. There are certain templates that are common to many people, and there are templates unique for a given person; the latter are obviously more valuable, but they can only be derived by analyzing the user’s existing passwords (we discussed that part in previous articles).
Examples:
- <firstname><2digits> – michael84
- <pet><symbol> – fluffy!
- <firstname><birthyear> – michael1984
- <team><2digits> – lakers23
- <surname><ddmm> – garcia1207
Templates describe patterns; masks and rule-based attacks implement these patterns. In Elcomsoft Distributed Password Recovery, the templates are generally used by choosing the dictionary and applying the various masks, as shown in the following example:
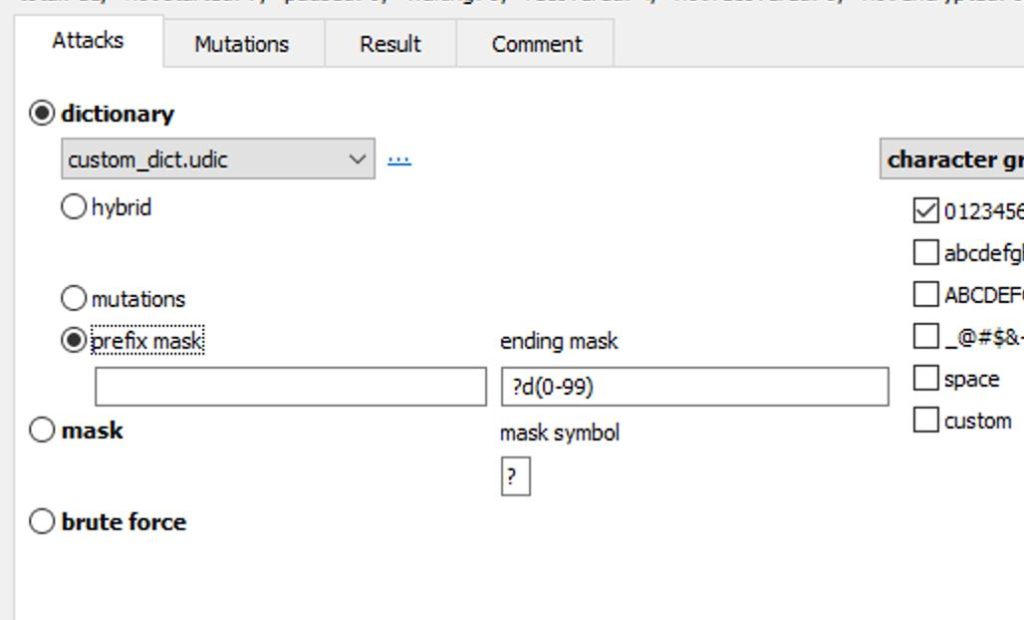
Mutations
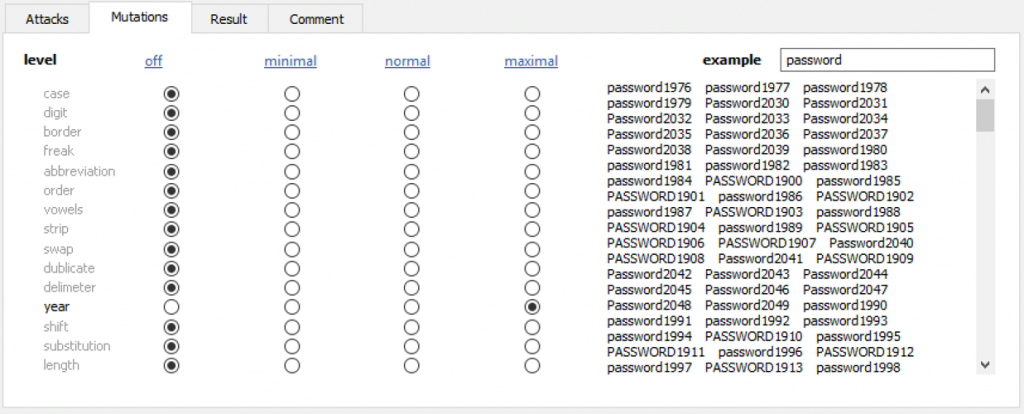
You can apply a broad set of semi-automated templates by employing the “mutations” feature instead of the “prefix mask” on the screenshot. With mutations, you can choose how the tokens from the custom dictionary will be modified in order to produce password candidates. The crucial part here is selecting only those mutations that are likely to be used by the person under investigation; the rules are the same as those for building templates.
Mutations define how simple tokens turn into full password candidates. Once we have a clean set of tokens (the custom dictionary), we can apply predictable transformations that mimic the way people modify familiar words to create passwords. These transformations are not random; users tend to follow consistent habits such as capitalizing the first letter, adding digits, inserting symbols, or replacing letters with similar-looking characters. By applying these rules systematically, a forensic specialist can expand a small set of personal tokens into thousands or millions of realistic variations while still keeping the search space tightly focused.
Most password recovery tools, including EDPR, implement these transformations as rule families. Case changes convert “michael” into variants such as “Michael” or “MICHAEL”. Digit mutations add numerical elements such as birth years or favorite numbers, turning “milo” into “milo91” or “91milo”, while year mutations append 4 digits representing a year (at higher strength, basic case mutations are also included). These rules can be combined to reflect how real users stack modifications, but mutation selection should depend on time budget and hardware performance: the more mutations you use, the larger the list of password candidates becomes.
The key is balancing thoroughness with speed. Each mutation family expands the candidate pool, but too many will generate a huge search space, slowing down recovery without improving success odds. The specialist must decide which mutations reflect actual human behavior for the target, and which combinations are worth the computational cost. The goal is not to produce every theoretical variation, but to produce the ones a person is most likely to have used.
Conclusion
A well-built targeted attack is not about generating millions of passwords; it is about generating the right ones in the right order. By breaking a user profile into clean tokens, ranking them by relevance, turning them into structured templates, and applying only realistic mutations, a forensic specialist can reduce search time drastically while increasing the chance of finding a working password early. The workflow is systematic, reproducible, and far more efficient than relying on generic dictionaries or uninformed brute force.
When applied carefully, this method bridges the gap between raw personal data and practical password recovery. It turns scattered biographical details into a focused, data-driven, personalized attack strategy that mirrors how real people build passwords. The result is a targeted attack tailored to the individual, helping investigators reach meaningful results faster and with fewer computational resources.



- iOS Forensic Toolkit 10.10 adds pairing-free sideloading of the extraction agent24 June, 2026
- Elcomsoft Phone Breaker 11.2: downloads iOS 26 iCloud backups18 June, 2026
- Elcomsoft Phone Breaker 11.1: reliable iCloud backup extraction26 May, 2026
- ElcomSoft Phone Breaker 11: full overhaul of iCloud extraction30 April, 2026
- iOS Forensic Toolkit 10.02 adds agent-based extraction for iOS 2629 April, 2026