Thunder Tables™ Explained
May 21st, 2009 by Andrey BelenkoCategory: «Cryptography», «General», «Security», «Software»
From time to time we’re receiving questions regarding various technologies used in our products, especially Thunder Tables™ and GPU acceleration. Today I’d like to explain what exactly Thunder Tables™ is (and what it’s not).
About Thunder Tables™
From user’s perspective Thunder Tables™ is a technology allowing fast and guaranteed decryption of Adobe PDF and Microsoft Word documents, it is currently supported in AOPB and APDFPR (Enterprise Editions only).
From technology perspective, Thunder Tables™ is time-memory tradeoff method based on Rainbow Tables and incorporating important improvements.
What is time-memory tradeoff?
If one needs to find key used to encrypt particular document then most straightforward way is to simply try all possible keys until one of them will match. This is called brute-force attack and it usually takes a lot of time.
Now, imagine there are many documents of same type encrypted on different key and we’d like to find all the keys. Doing brute-force on each of them is not very smart. Much better option is to build lookup table containing all possible keys so that to find key for particular document you need to perform only one table lookup. So, to be able to find keys faster we need to spend some time in pre-computing table and we also need some memory to store table. This is exactly what time-memory tradeoff is: making key search faster at the cost of precomputations and storage. Here’s what Wikipedia thinks about this:
«In computer science, a space-time or time-memory tradeoff is a situation where […] the computation time can be reduced at the cost of increased memory use. [..] Often, by exploiting a space-time tradeoff, a program can be made to run much faster»
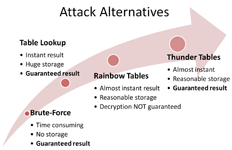
Example with lookup table is an extreme one and not very practical because of its storage requirements: for 40-bit key you need 5 terabytes to store such table. To be practical time-memory tradeoff should require reasonable amount of storage (say, few gigabytes) and provide significant speedup over brute-force (say, 1000 times faster). That’s where Rainbow Tables come into play.
Rainbow Tables
Rainbow Tables were introduced in 2003 by Philippe Oechslin in «Making a Faster Cryptanalytic Time-Memory Trade-Off». This work is a simple yet very smart improvement of approach described by Martin Hellman in 1980 in «A Cryptanalytic Time-Memory Trade-Off». Original Hellman’s method, however, had some drawbacks which has limited it’s applicability in practice.
Rainbow Tables are perfectly suited for both password recovery encryption key recovery, but Philippe was focused on passwords in his work and I think that’s the reason why most software was also focused on applying Rainbow Tables to password recovery. First software utilizing Rainbow Tables to decrypt documents, ophcrack_office by Philippe Oechslin, appeared in late 2006. It supported Microsoft Word and Excel documents with 40-bit encryption. Elcomsoft was first to successfully apply Rainbow Tables to decrypt PDF documents with 40-bit encryption, APDFPR with this feature appeared in early 2007.
One important limitation of Rainbow Tables (which is inherited from original Hellman’s method) is that it is not possible to achieve 100% success probability with it. Most Rainbow Tables have success rate in the range 97-99% which is quite high, but if you have many files to process chances that Rainbow Tables will fail for one of them are getting higher. Thunder Tables™ remove this restriction.
Thunder Tables™
Let’s assume there are 100 encrypted Word documents which we need to decrypt. Running them trough Rainbow Tables with 99% success rate will on average decrypt 99 and fail for one document, for which we’ll have to launch very slow brute-force attack. You can expect 99 out of 100 files to be decrypted in less than four hours but this one last file will take few days to decrypt. What is even worse, 99% of that brute-force time will be spent in vain because 99% of all possible keys are in Rainbow Tables and if document was encrypted with one of those 99% keys then Rainbow Table would have found it. So, there are only 1% of possible keys left, but brute-force doesn’t “know” about this.
To address this problem Thunder Tables™ contain additional file which lists all keys for which Rainbow Table fails. That is, if Rainbow Table attack on particular document fails, brute-force now “knows” which keys to check and will not spend time trying 99% of incorrect keys.
This idea looks very simple, but the problem is how to implement it, particularly how to build magic file with keys for which Rainbow Table attack will fail. You can’t just run every key through Rainbow Tables attack — it will take forever. You can, in theory, build a bitmap of keys in RAM, but you’ll need 128 GB of RAM for 40 bits which is kind of rare today (and was even rarer two years ago when we invented this). We had to be creative and finally we found the way. Thunder Tables™ for PDF were built on single Intel Core2 CPU with only 1 GB of RAM.
Usage Notes
Thunder Tables™ are about 4 GB for each document type and they are shipped on DVD. DVDs are good for archiving data, but you definitely should not try to use them for actual attack — it will be too slow. Copy tables to hard drive or (much better) to USB Flash Drive. Specify location of tables in program settings and it will use them automatically.
Thunder Tables™ can be used to decrypt Microsoft Word and Adobe PDF documents. For Microsoft Excel we provide conventional Rainbow Tables with success rate about 97.5%. Reason for not providing Thunder Tables™ for it is because Excel uses very complicated file format and it is generally impossible to predict which data will be stored at where in a file. This knowledge is required to mount successful Thunder Tables™ or Rainbow Tables attack. According to our statistics, 3-5% of Excel files (created not only with Microsoft Excel but also with other compatible tools) have some features which can prevent successful usage of Rainbow Tables. This is why even if we build Thunder Tables™ for Microsoft Excel (which is not very difficult to do) we still cannot guarantee decryption with those tables because of Excel file format peculiarities. And this is also why there is no real sense in pursuing success probabilites higher than 97% — chances of getting "incompatible" file are just higher than chances that attack will fail.
REFERENCES:

Advanced Office Password Breaker
Break passwords and unlock documents instead of performing lengthy password recovery. Advanced Office Password Breaker unlocks password-protected Microsoft Word documents and Excel spreadsheets within a guaranteed timeframe instead of attacking and recovering the complex passwords. Need the documents unlocked faster? Speed up the recovery by using multi-processor or multi-core systems or several computers and get your data back in almost no time.
Advanced Office Password Breaker official web page & downloads »

Advanced PDF Password Recovery
Unlock PDF documents and remove editing, printing and copying restrictions instantly. Open encrypted and password-protected PDF documents quickly and efficiently. The unique, patented Thunder Tables® technology guarantees the recovery of 40-bit keys in under a minute! The multi-threaded low-level code is optimized for modern multi-core PCs, ensuring the best performance and the quickest recovery of the most complex passwords.
Advanced PDF Password Recovery official web page & downloads »



- iOS Forensic Toolkit 10.02 adds agent-based extraction for iOS 2629 April, 2026
- Elcomsoft Quick Triage receives a major update28 April, 2026
- Elcomsoft System Recovery 8.37 expands support for Microsoft Accounts, adds Entra ID23 April, 2026
- iOS Forensic Toolkit 10.01 expands agent-based extraction up to iOS 18.7.1 for M-series iPads 21 April, 2026
- iOS Forensic Toolkit 10.0 expands agent-based extraction up to iOS 18 14 April, 2026